
1. 如果你已经用过大语言模型,大概率写过类似这样的代码:
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=128)
text = tokenizer.decode(outputs[0])
这段代码很简单,也很适合做实验。
但是,如果我们把场景从“本地跑一个 demo”换成“线上同时服务几百个用户”,问题马上就变了。
一个用户问:“帮我总结这篇文章。”
另一个用户问:“帮我写一段 SQL。”
第三个用户上传了一大段上下文,然后只希望模型回答一句话。
第四个用户要求模型连续生成几千个 token。
这些请求长度不同,生成长度不同,到达时间不同,结束时间也不同。我们不能简单地把它们塞进一个固定 batch 里,然后等所有请求都结束。那样会造成大量等待,也会让 GPU 经常处在没有被充分利用的状态。
更麻烦的是,LLM 推理并不是普通的神经网络推理。
在图像分类里,一个请求通常就是一次 forward。输入进来,模型算一次,输出类别,结束。
但在文本生成里,一个请求会被拆成很多轮。模型先处理完整 prompt,然后每次生成一个新 token,再把这个 token 接回上下文,继续生成下一个 token。也就是说,一个用户请求不是一次计算,而是一段持续的计算过程。
这就是为什么 LLM serving 要比普通模型 serving 复杂得多。
vLLM 这类系统真正解决的问题,不是“怎么调用模型”,而是“怎么高效地组织大量请求的推理过程”。
这个系列的目标,就是从零实现一个 mini vLLM。它不会一开始就追求工业级性能,也不会直接写复杂 CUDA kernel。我们会先做一个正确、清晰、可运行的版本,然后逐步把它优化成一个具备核心推理引擎能力的小系统。
最终,我们希望这个 mini vLLM 至少具备这些能力:
支持基本的 LLM 文本生成
支持 KV cache
区分 prefill 和 decode 阶段
支持多个请求的动态调度
支持 continuous batching
支持 block 级别的 KV cache 管理
实现一个教学版 PagedAttention
支持流式输出
提供简单的 HTTP 服务接口
能够做基础 benchmark
如果你想深入理解 vLLM、SGLang、TGI、TensorRT LLM 这类推理系统,这个项目会是一个很好的切入口。
2. LLM 推理到底在慢什么
我们先看一个最朴素的生成过程。
用户输入一个 prompt:
Explain KV cache in LLM inference.
模型不会一次性直接生成完整答案。它的生成过程大致是这样的:
输入 prompt
生成第 1 个 token
生成第 2 个 token
生成第 3 个 token
...
直到遇到停止条件
每生成一个 token,模型都要执行一次 forward。对于一个生成 512 个 token 的请求来说,decode 阶段就需要执行 512 轮。
更具体一点,LLM 推理通常分成两个阶段。
第一个阶段叫 prefill。
prefill 阶段会一次性处理用户输入的 prompt。假设 prompt 有 1024 个 token,那么模型需要对这 1024 个 token 做一次完整计算,并把每一层 attention 里的 key 和 value 保存下来。
第二个阶段叫 decode。
decode 阶段每一轮只输入刚刚生成的一个 token。虽然输入只有一个 token,但这个 token 在 attention 里仍然要看到之前所有 token 的上下文。因此,模型需要访问历史 token 对应的 key 和 value。
这些历史 key 和 value,就是 KV cache。
如果没有 KV cache,每生成一个新 token,都要把完整上下文重新算一遍。这样生成越长,重复计算越多,性能会非常差。
有了 KV cache 之后,模型可以复用之前已经算好的 key 和 value。decode 阶段只需要计算新 token 的 key 和 value,然后把它们追加到缓存里。
这听起来很美好,但它带来了一个新的问题:KV cache 会占用大量显存。
而且它不是固定大小的。
有的请求 prompt 很短,生成也很短。
有的请求 prompt 很长,生成也很长。
有的请求很快结束,有的请求会持续很久。
在线上服务场景里,KV cache 的生命周期是动态的。它会不断创建、增长、释放。如果管理不好,就会出现显存浪费、碎片化、batch size 上不去等问题。
所以 LLM 推理系统的核心瓶颈,往往不是“模型会不会 forward”,而是这几个问题:
怎么管理大量请求的生命周期
怎么让 GPU 每一轮都尽量忙起来
怎么高效复用 KV cache
怎么避免 KV cache 浪费显存
怎么在延迟和吞吐之间做调度权衡
这也是我们这个系列要一步步解决的问题。
3. 朴素 generate 函数为什么不够
我们可以先想象一个最简单的服务。
每来一个请求,就调用一次 model.generate。
伪代码大概是这样:
def handle_request(prompt: str) -> str:
input_ids = tokenizer.encode(prompt)
output_ids = model.generate(input_ids)
return tokenizer.decode(output_ids)
这个版本非常直观,但问题也非常明显。
第一个问题是并发能力差。
如果每个请求都单独跑一次 generate,那么 GPU 可能无法被充分利用。尤其是在 decode 阶段,每轮只处理一个 token,计算粒度很小,GPU 很容易吃不满。
第二个问题是请求之间不能共享调度。
假设请求 A 需要生成 20 个 token,请求 B 需要生成 2000 个 token。如果我们把它们放进一个固定 batch 里,请求 A 很快就结束了,但 batch 可能还要等请求 B 继续生成。固定 batch 会造成浪费。
第三个问题是新请求不能灵活加入。
线上请求不是一批一批整齐到达的,而是随时到达的。如果系统必须等当前 batch 完全结束,才能处理下一批请求,那么排队延迟会很高。
第四个问题是 KV cache 管理粗糙。
最简单的做法是为每个请求分配一大段连续显存,最多能生成多少 token,就提前准备多少空间。但实际生成长度往往不可预测。提前分配太少,可能不够用;提前分配太多,又会浪费显存。
这时我们就能理解,为什么一个高性能 LLM 推理系统需要自己的 engine、scheduler、cache manager 和 model runner。
它不是在重复造 Hugging Face 的轮子,而是在解决线上推理里的系统问题。
4. mini vLLM 要实现什么
这个系列里,我们会实现一个教学版推理引擎。为了避免一上来陷入复杂工程,我们先给它起一个名字:mini vLLM。
它的目标不是完整复刻 vLLM,而是实现 vLLM 最核心的思想。
我们希望它的整体结构大概长这样:
mini_vllm/
api/
server.py
protocol.py
engine/
llm_engine.py
scheduler.py
request.py
sequence.py
worker/
model_runner.py
executor.py
model/
transformer.py
attention.py
sampler.py
cache/
block_manager.py
kv_cache.py
prefix_cache.py
benchmark/
throughput.py
latency.py
这几个模块分别负责不同的事情。
api 层负责对外提供服务接口。后面我们会做一个简单的 HTTP server,让用户可以像调用普通 LLM API 一样调用我们的 mini vLLM。
engine 层是整个系统的大脑。它负责接收请求、维护请求状态、调用调度器、驱动模型执行、收集输出 token。
scheduler 负责决定每一轮要跑哪些请求。它要处理 waiting、running、finished 这些状态,还要决定哪些请求可以进入 prefill,哪些请求继续 decode。
worker 层负责真正执行模型。它会把 scheduler 给出的 batch 转成模型输入,调用模型 forward,然后把 logits 交给 sampler。
model 层负责最小 Transformer 推理逻辑。为了降低复杂度,前期我们可以直接接 Hugging Face 模型,后期再逐步替换其中的 attention 和 sampling。
cache 层负责 KV cache 管理。这个模块会从最简单的连续 cache 开始,逐渐演进到 block manager,再到教学版 PagedAttention。
benchmark 层负责测量性能。我们不能只说优化了,还要用数据展示吞吐和延迟的变化。
这个设计有一个好处:每篇文章都能落到一个明确模块上,而不是泛泛而谈。
5. 这个系列会怎么展开
整个系列会分成几个阶段。
第一阶段,我们先跑通最小 LLM 推理闭环。
我们会实现一个最朴素的 generate 函数,理解 tokenizer、input ids、logits、sampling、stop condition 这些基本概念。然后我们会加入 KV cache,让 decode 不再重复计算完整上下文。
第二阶段,我们会实现请求抽象和调度器。
这一步会把单请求 generate 改造成多请求 engine。我们会设计 Request、Sequence、SequenceGroup、SamplingParams 这些数据结构,然后用 waiting、running、finished 队列维护请求生命周期。
第三阶段,我们会实现 continuous batching。
这一步是推理系统和普通 batch 推理拉开差距的地方。我们会让系统在每一轮 decode 时动态加入新请求,也能及时移除已经完成的请求,从而提高 GPU 利用率。
第四阶段,我们会实现 block 级别的 KV cache 管理。
最初的 KV cache 会使用连续显存,但这会造成浪费。后面我们会把 KV cache 拆成固定大小的 block。每个请求不再拥有一整段连续 cache,而是拥有一张 block table。这样可以更灵活地分配和释放显存。
第五阶段,我们会实现教学版 PagedAttention。
PagedAttention 的核心思想,可以类比操作系统里的分页机制。逻辑上,一个请求看到的是连续的 token 序列;物理上,这些 token 的 KV cache 可以分散在不同 block 里。attention 计算时,通过 block table 找到真正的 K 和 V。
第六阶段,我们会完善工程能力。
包括流式输出、HTTP API、benchmark、prefix caching、chunked prefill、speculative decoding、多 GPU 和量化推理等主题。
每一步都会尽量遵循一个原则:先写正确,再谈性能。
如果一个优化还没有被清楚地理解,就不要急着上复杂 kernel。
6. 我们不会一开始就做什么
为了让这个系列可完成、可阅读、可运行,我们一开始不会做这些事情:
不从第一篇就写 CUDA kernel
不一开始就支持多 GPU
不一开始就支持 MoE 模型
不一开始就支持复杂量化格式
不一开始就兼容所有 OpenAI API 字段
不一开始就追求和真实 vLLM 一样的性能
这并不是说这些不重要。
恰恰相反,它们都很重要。但如果一开始就把所有复杂度都打开,读者很容易迷失在工程细节里,看不到主线。
我们的路线是先搭骨架,再补肌肉,最后再做性能优化。
第一版 mini vLLM 只需要能清楚展示这些核心问题:
一个请求在系统里如何流动
prefill 和 decode 如何被调度
KV cache 如何被创建、追加和释放
多个请求如何组成 batch
PagedAttention 如何解决 KV cache 显存管理问题
只要这几个问题讲清楚,这个系列就已经有很高的学习价值。
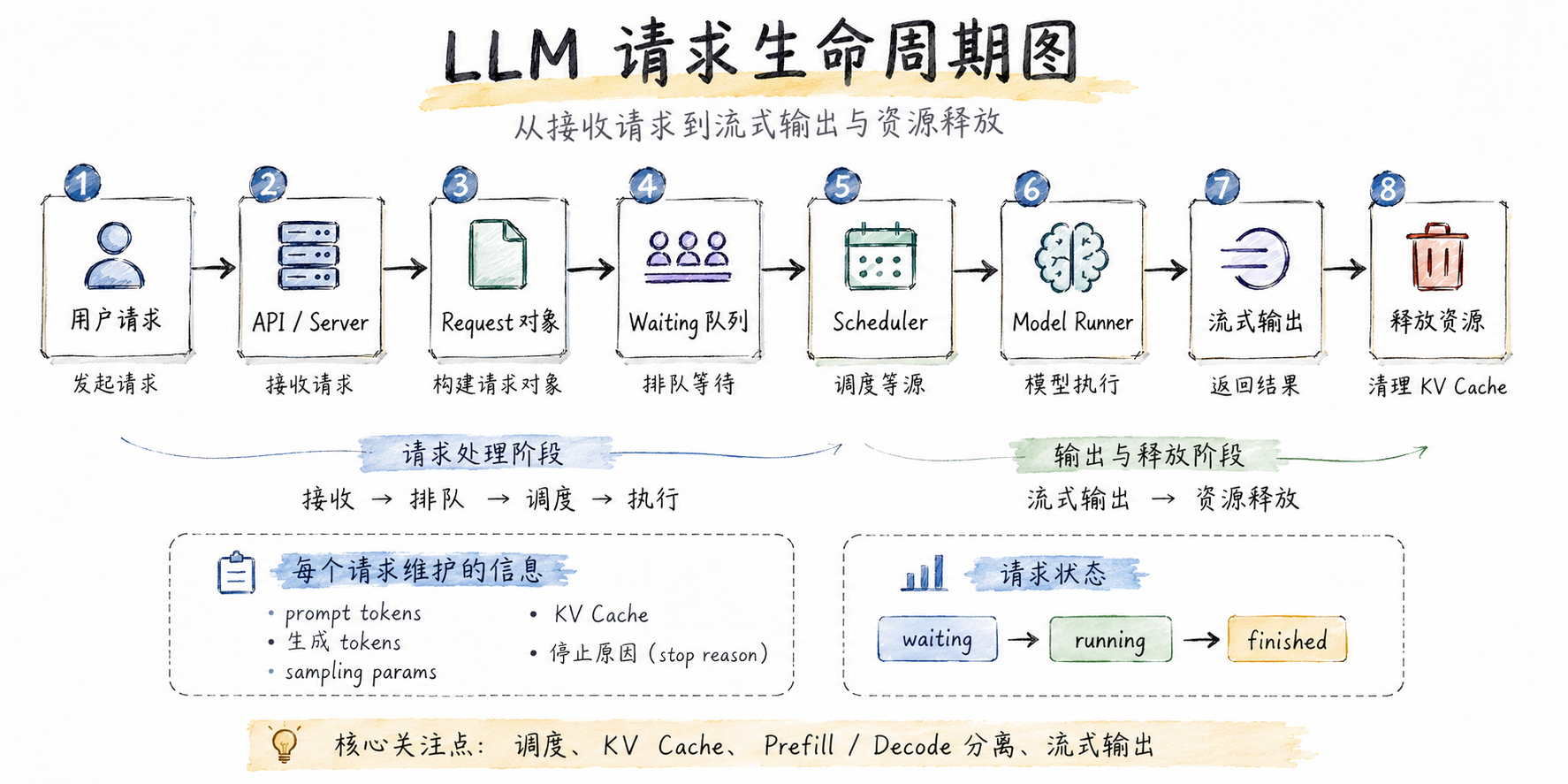
7. 从一个请求看完整链路
为了让后续文章更容易展开,我们先用一个请求走一遍理想中的系统链路。
用户发送请求:
{
"prompt": "Explain KV cache in LLM inference.",
"max_tokens": 128,
"temperature": 0.8
}
服务层收到请求后,会把它转换成一个内部 Request 对象。
request = Request(
request_id="req_001",
prompt="Explain KV cache in LLM inference.",
sampling_params=SamplingParams(
max_tokens=128,
temperature=0.8,
),
)
然后 tokenizer 会把 prompt 转成 token ids。
prompt_token_ids = tokenizer.encode(request.prompt)
engine 会把这个请求放入 waiting 队列。
scheduler.add_request(request)
调度器在下一轮调度时,发现这个请求还没有做 prefill,于是把它选出来,构造 prefill batch。
batch = scheduler.schedule()
outputs = model_runner.execute(batch)
模型执行完成后,会返回 logits 和 KV cache。
sampler 根据 logits 采样出下一个 token。
next_token = sampler.sample(logits)
如果请求还没结束,它会进入 running 队列,等待下一轮 decode。
decode 阶段每一轮只处理新增 token,但会不断访问之前保存的 KV cache。
while not sequence.is_finished:
batch = scheduler.schedule()
outputs = model_runner.execute(batch)
next_token = sampler.sample(outputs.logits)
sequence.append_token(next_token)
如果用户开启了流式输出,engine 会把生成的新 token 立即返回给客户端。
yield next_token
当遇到停止 token,或者生成 token 数达到 max_tokens,请求结束。调度器释放它占用的 KV cache block,并把它移入 finished 状态。
这就是一个 LLM 请求在推理引擎里的完整生命周期。
后面的文章,本质上就是把这条链路一步步实现出来。
8. 本系列的代码目标
为了让项目足够清晰,我们会尽量保持代码简单。
第一版代码会优先保证三件事:
容易读
容易跑
容易验证正确性
在这个基础上,再逐步加入性能优化。
例如 KV cache 管理,我们不会一开始就写成复杂的 paged attention kernel,而是分三步走。
第一步,使用最简单的连续 KV cache。
第二步,实现 block manager,让每个请求维护自己的 block table。
第三步,基于 block table 实现一个 PyTorch 版本的 PagedAttention。
这样读者可以清楚看到:每一个复杂设计都是为了解决前一个版本暴露出来的问题。
这也是我认为学习系统工程最有效的方式。
不要直接阅读最终形态,而是观察它为什么一步步长成这样。
9. 第一阶段结束后会得到什么
当我们完成前几篇文章时,mini vLLM 应该能完成这样的事情:
engine = LLMEngine(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0")
request_id = engine.add_request(
prompt="Explain KV cache in LLM inference.",
max_tokens=128,
temperature=0.8,
)
while True:
outputs = engine.step()
for output in outputs:
print(output.text, end="", flush=True)
if engine.is_finished(request_id):
break
这段代码背后会包含一个最小推理引擎。
它不再只是调用 model.generate,而是自己维护请求状态,自己执行 step,自己采样 token,自己判断请求是否结束。
这就是从“调用模型”到“实现推理系统”的第一步。
10. 总结
这一篇是整个系列的开篇。
我们讨论了为什么 LLM serving 不能简单地等同于 model.generate,也解释了为什么 vLLM 这类系统的核心在于推理调度和 KV cache 管理。
接下来,我们会正式开始写代码。
下一篇文章,我们会从最朴素的单请求 generate 函数开始,实现一个最小可运行的 LLM 推理闭环。我们会手动完成 tokenizer、模型 forward、logits 处理、采样和停止条件判断。
这看起来很基础,但它是后面所有复杂系统的起点。
只有先理解一个 token 是怎么被生成出来的,才能真正理解几千个请求是怎么被高效调度起来的。



